library(palmerpenguins)
library(dplyr)Automating sentences with R
annotations
data-visualisation
r-how-to
parameterised-plots
Automating text in R, and making the output look human.
Making even the write-up reproducible
The thing that first drew me to R was the ability to run the same analysis on different datasets and get a similar output every time - the same graphs, the same analyses, the same structure to the report, but different data, so a different story to tell. We often talk about the power of R in making research analyses reproducible, or in generating parameterised reports which all include variants of the same graphs, but one thing we haven’t talked much about is the role R can play in automating some of the write-up in this line of work. Some of the write-up requires your expertise, but some of it really doesn’t. What if we could automate the bits of it that don’t require your expertise?
If you find yourself repeatedly writing things like “the value of [ABC] was [X]; this is below the recommended value ([Y]); you should consider doing [Z] to address this”, then read on! We may be about to save you a lot of time…
Using R for text automation
You may already know about using inline code to add code outputs into sentences within an Rmd or Quarto document. Things like this…
* Two plus two equals `r 2+2`
* The number of letters in "antidisestablishmentarianism" is `r stringr::str_count("antidisestablishmentarianism")`… give us outputs like this:
- Two plus two equals 4
- The number of letters in “antidisestablishmentarianism” is 28
But what it we could make it more sophisticated so that it mimics the way you would write up the outcomes of your analyses? Time for a demo using the trusty {palmerpenguins}. We’re going to build our way towards the following output, which is entirely automated using few simple data wrangling tricks.
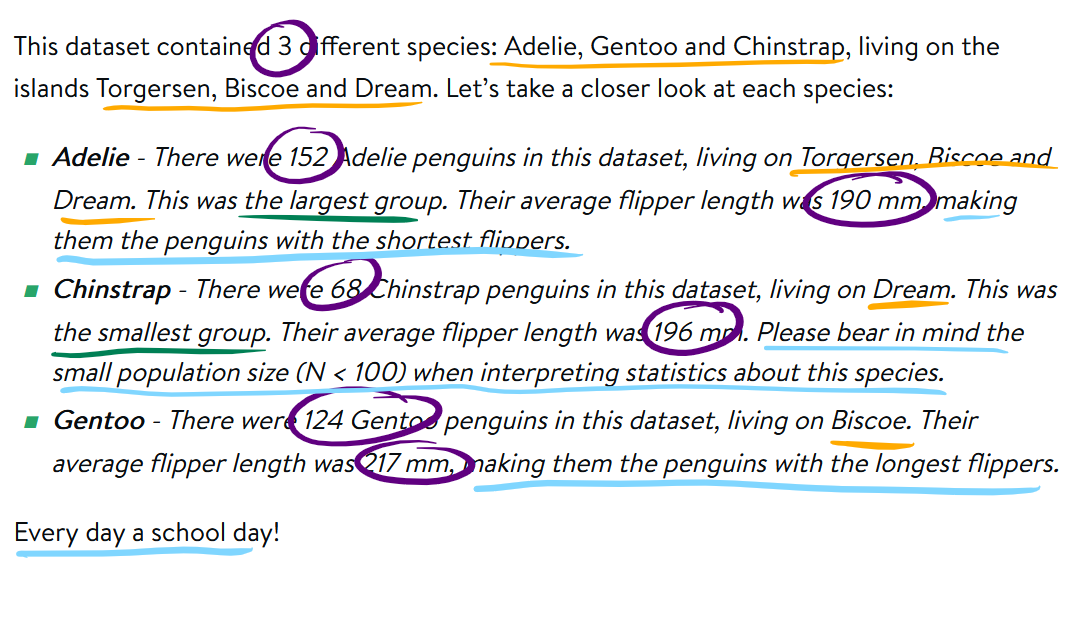
This dataset contained 3 different species: Adelie, Gentoo and Chinstrap, living on the islands Torgersen, Biscoe and Dream. Let’s take a closer look at each species:
- Adelie - There were 152 Adelie penguins in this dataset, living on Torgersen, Biscoe and Dream. This was the largest group. Their average flipper length was 190 mm, making them the penguins with the shortest flippers.
- Chinstrap - There were 68 Chinstrap penguins in this dataset, living on Dream. This was the smallest group. Their average flipper length was 196 mm. Please bear in mind the small population size (N < 100) when interpreting statistics about this species.
- Gentoo - There were 124 Gentoo penguins in this dataset, living on Biscoe. Their average flipper length was 217 mm, making them the penguins with the longest flippers.
Every day a school day!
Building sentences one trick at a time
Let’s load our data and the {dplyr} package, which contains the functions we’ll need to get the text ready.
Lists
For our first trick, we’ll turn vectors into sentence-like lists. Let’s create a function that allows us to paste a vector as we would normally write a list in a sentence: the first components are separated by a comma, and we have an “and” before the last component.
If we just use paste with “and” as the “collapse” string, we end up with this.
paste(c("a", "b", "c"), collapse = " and ")[1] "a and b and c"Not quite what we’re after! So, what we need to do is create a function that takes “a” and “b” (all items other than the last item) and separates them with a comma, and then add something to the end of that.
my_vector <- c("a", "b", "c")
paste(my_vector[1:length(my_vector) - 1], collapse = ", ")[1] "a, b"Now we can combine these two:
# The first item is N-1 items separated by " ,"
paste(c(paste(my_vector[1:length(my_vector) - 1], collapse = ", "),
# ... to which we add the Nth item...
my_vector[length(my_vector)]),
# and we're separating them using " and "
collapse = " and ")[1] "a, b and c"The trouble with this is if we have an item that is of length 1, we get a strange output:
my_vector <- c("penguins!")
cat("this dataset contains ",
paste(paste(my_vector[1:length(my_vector) - 1], collapse = ", "),
"and",
my_vector[length(my_vector)]))this dataset contains and penguins!So we need something a bit more sophisticated. Let’s write a function that creates a different output based on whether the vector is of length 1 or greater than 1:
listify <- function(my_vector) {
if(length(my_vector) > 1) {
paste(paste(my_vector[1:length(my_vector)-1],
collapse = ", "),
"and",
my_vector[length(my_vector)])
} else {
# if length == 1, we don't want to print "and blah"
paste(my_vector)
}
}We can then include the following sentence with inline code chunks in our markdown file.
This dataset contained `r penguins %>% pull(species) %>% unique() %>% length`
different species: `r penguins %>% pull(species) %>% unique() %>% listify()`,
living on the islands `r penguins %>% pull(island) %>% unique() %>% listify()`. This dataset contained 3 different species: Adelie, Gentoo and Chinstrap, living on the islands Torgersen, Biscoe and Dream.
So far so good!
Comparisons
Let’s now add a few simple calculations and comparisons, so that we can include those in our report.
summary <- penguins %>%
ungroup() %>%
group_by(species) %>%
summarise(population = length(island),
island = paste(listify(unique(island))),
flipper_length = round(mean(flipper_length_mm, na.rm = TRUE))) %>%
mutate(pop_comparison = case_when(population == min(population) ~ "smallest",
population == max(population) ~ "largest"),
flipper_comparison = case_when(flipper_length == min(flipper_length) ~ "shortest",
flipper_length == max(flipper_length) ~ "longest"))Now that we’ve computed these values and set up the comparison words in an r code chunk, we can add the following sentence with inline code chunks to our RMarkdown file…
The Adelie population made up `r filter(summary, species == "Adelie") %>%
pull(population)` of our penguins, the `r filter(summary, species == "Adelie") %>%
pull(pop_comparison)` group in the dataset. Their mean flipper length was
`r filter(summary, species == "Adelie") %>% pull(flipper_length)`mm, the
`r filter(summary, species == "Adelie") %>% pull(flipper_comparison)` across the
`r length(summary$species)` groups.…which produces this:
The Adelie population made up 152 of our penguins, the largest group in the dataset. Their mean flipper length was 190mm, the shortest across the 3 groups.
Recommendations
You may wish to add conditional recommendations to your write-up. For example, if a measurement was below a desired threshold and the reader needs to take action to rectify this, or if there was a lot of missing data. Here, we’ve gone with a simple flag, but you can make this as complex as you like; case_when() is a powerful tool!
Let’s use a code chunk to add the recommendations into our summary tibble.
summary <- summary %>%
mutate(recommendation = case_when(population < 100 ~
"Please bear in mind the small population size (N < 100) when interpreting statistics about this species."))And now for the RMarkdown sentence…
Chinstrap penguins have a mean flipper length of `r filter(summary,
species == "Chinstrap") %>% pull(flipper_length)` mm. `r filter(summary,
species == "Chinstrap") %>% pull(recommendation)`… which produces this:
Chinstrap penguins have a mean flipper length of 196 mm. Please bear in mind the small population size (N < 100) when interpreting statistics about this species.
A human touch (kind of)
As a bonus trick, if your report contains sentences that will be identical aside from the values and comparisons, it could get really quite repetitive. Time to inject a few random comments!
positive_comments <- c("Fantastic!",
"Fascinating stuff!",
"That's all good to hear!",
"Every day a school day!")Now we’ve created that vector of positive comments, we can call on it within the text as follows…
Adelie are the `r filter(summary, species == "Adelie") %>% pull(pop_comparison)`
group of penguins in the dataset (N = `r filter(summary, species == "Adelie") %>%
pull(population)`). `r sample(positive_comments, 1)`… resulting in:
Adelie are the largest group of penguins in the dataset (N = 152). That’s all good to hear!
Applying the same piece of code to every species in the dataset
In each of the examples above, we’ve been filtering by species and creating a sentence from the subsequent columns in our summary data. What we really want to do is apply the same piece of code to the data corresponding to each species, so we can produce a report which summarises our key findings for all of them. Enter purr::walk()! For this to work, we need to use cat() inside a code chunk, and set the results option to results = 'asis'.
First let’s write our cat function.
print_species_summary <- function(this_species){
filtered_summary <- filter(summary,
species == this_species)
cat("\n * **", this_species, "** - ", sep = "")
cat("The average flipper length among the ", this_species,
" population in this dataset was ",
filtered_summary %>% pull(flipper_length),
"mm.")
}And now we can use purr::walk() to apply that function to each of our species:
list_of_species <- penguins %>%
pull(species) %>%
unique() %>%
# The species are factors, so we need to retrieve them as
# character, otherwise, it just prints their levels (1, 2, and 3!)
as.character()
purrr::walk(list_of_species, print_species_summary)Which results in:
- Adelie - The average flipper length among the Adelie population in this dataset was 190 mm.
- Gentoo - The average flipper length among the Gentoo population in this dataset was 217 mm.
- Chinstrap - The average flipper length among the Chinstrap population in this dataset was 196 mm.
Pulling it all together
Combining all these tricks, we can automate the write-up across the species, including more information without losing the human-sounding sentences! Here’s the content of the RMarkdown file:
```{r setting_things_up}
print_species_summary <- function(this_species){
filtered_summary <- filter(summary,
species == this_species)
cat("\n * **", this_species, "** - ", sep = "")
# Population size
cat("There were",
filtered_summary %>%
pull(population),
this_species,
"penguins in this dataset, ")
# Location
cat(" living on ",
filtered_summary %>% pull(island),
". ",
sep = "")
# Population comment if applicable
if(!is.na(filtered_summary %>% pull(pop_comparison))) {
cat("This was the ",
filtered_summary %>% pull(pop_comparison),
" group.")
}
# Flippers
cat("Their average flipper length was",
filtered_summary %>% pull(flipper_length),
"mm", sep = " ")
# Flipper comment if applicable
if(is.na(filtered_summary %>% pull(flipper_comparison))) {
cat(".")
} else {
cat(", making them the penguins with the ",
filtered_summary %>% pull(flipper_comparison),
"flippers.")
}
# Overall comment/recommendation if applicable
if(!is.na(filtered_summary %>% pull(recommendation))) {
cat(" ", filtered_summary %>% pull(recommendation))
}
}
list_of_species <- penguins %>%
pull(species) %>%
unique() %>%
# The species are factors, so we need to retrieve them as
# character, otherwise, it just prints their levels (1, 2, and 3!)
as.character()
```
This dataset contained `r penguins %>% pull(species) %>% unique() %>% length`
different species: `r penguins %>% pull(species) %>% unique() %>% listify()`,
living on the islands `r penguins %>% pull(island) %>% unique() %>% listify()`.
Let's take a closer look at each species:
```{r use_printing_function, results='asis'}
purrr::walk(list_of_species, print_species_summary)
```
`r sample(positive_comments, 1)`And here’s the output:
This dataset contained 3 different species: Adelie, Gentoo and Chinstrap, living on the islands Torgersen, Biscoe and Dream. Let’s take a closer look at each species:
- Adelie - There were 152 Adelie penguins in this dataset, living on Torgersen, Biscoe and Dream. This was the largest group.Their average flipper length was 190 mm, making them the penguins with the shortest flippers.
- Gentoo - There were 124 Gentoo penguins in this dataset, living on Biscoe. Their average flipper length was 217 mm, making them the penguins with the longest flippers.
- Chinstrap - There were 68 Chinstrap penguins in this dataset, living on Dream. This was the smallest group.Their average flipper length was 196 mm. Please bear in mind the small population size (N < 100) when interpreting statistics about this species.
Every day a school day!
All automated, but it reads as if you’d written it - which you have really, just via code! sample(positive_comments, 1) 😉
Reuse
Citation
For attribution, please cite this work as:
Thompson, Cara, and list(name = "Cara Thompson", url = list()). 2022.
“Automating Sentences with R.” September 9, 2022. https://www.cararthompson.com/posts/2022-09-09-automating-sentences-with-r/automating-sentences-with-r.html.