# The default plural is an s tagged onto the end of the word ...
verbaliseR::pluralise("penguin", 3)
# ... but this can be changed ...
verbaliseR::pluralise("bateau", 3, plural = "x", include_number = FALSE)
# ... or a new word can be substituted
verbaliseR::pluralise("sheep", 3, plural = "sheep", add_or_swap = "swap")🚨 New #rstats package: verbaliseR
r-how-to
annotations
A bundle of functions that help turn #rstats output into human-looking sentences, with the fun quirks of the English language.
Quick demo🧵 of its main functions: pluralise, listify, prettify_date and restore_capitals.
First up, pluralise()!

pluralise() uses num_to_text(), which can also be used as a stand-alone function. It only writes numbers out in full if they are - at the start of a sentence (but smaller than 1001) - within a sentence and no greater than 10 - whole numbers
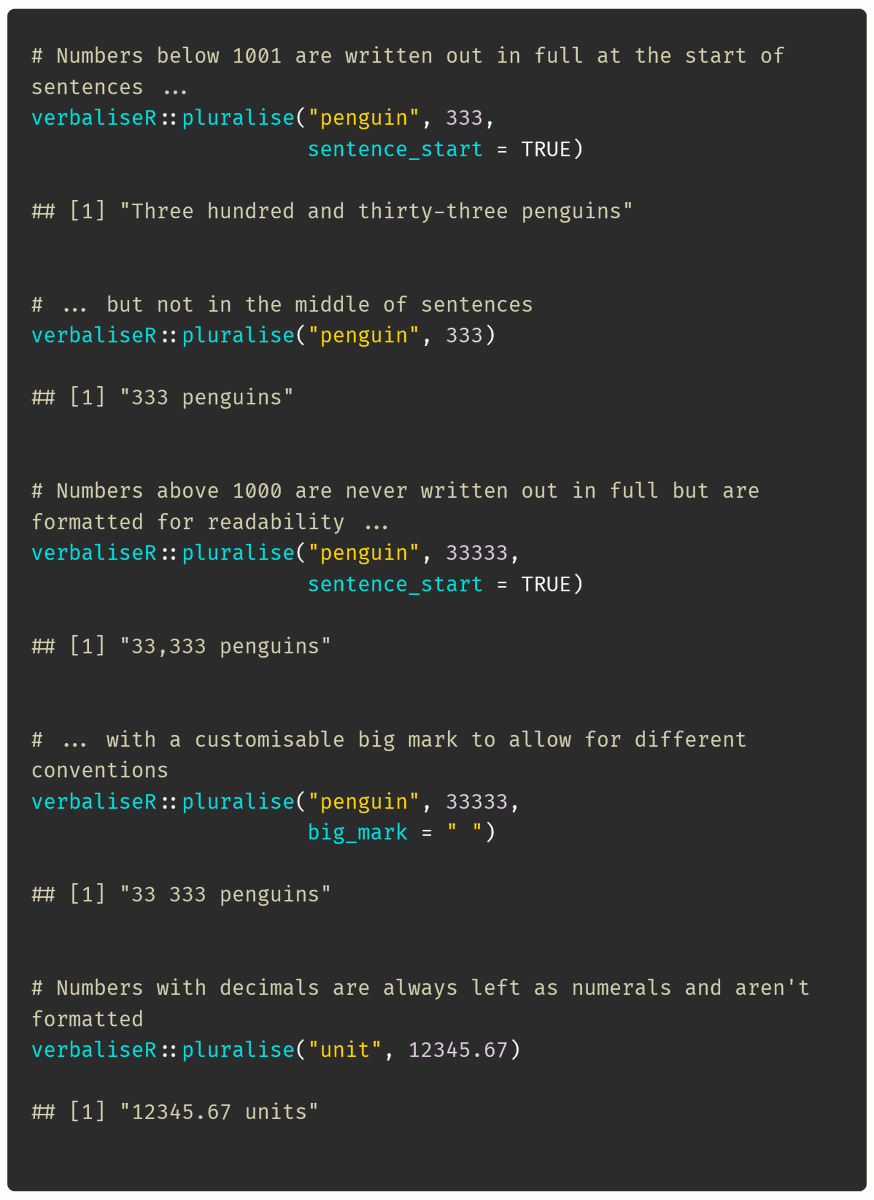
# Numbers below 1001 are written out in full at the start of sentences ...
verbaliseR::pluralise("penguin", 333, sentence_start = TRUE)
# ... but not in the middle of sentences
verbaliseR::pluralise("penguin", 333)
# Numbers above 1000 are never written out in full but are formatted for readability ...
verbaliseR::pluralise("penguin", 33333, sentence_start = TRUE)
# ... with a customisable big mark to allow for different conventions
verbaliseR::pluralise("penguin", 33333, big_mark = " ")
# Numbers with decimals are always left as numerals and aren't formatted
verbaliseR::pluralise("unit", 12345.67)Next, prettify_date()
I have always found formatting dates fiddly, so I built myself this shortcut and expanded it with a few linguistic niceties.
It defaults to UK style, but also does US style if you prefer!

Third, listify() with options to use with or without the oxford comma!
This is a fun one to play with, combining several listify() calls to create more complex sentences; and why not switch languages also?

And finally, restore_capitals()
which comes in handy if you’ve just used something like stringr::str_to_sentence() to get rid of all caps or some other capitalisation anomaly in the data.
(see x.com/cararthompson/status/1565324232715821056)

Outro
In all this, I’ve been keen not to reinvent the wheel, so here are a few other functions to explore if you’re looking to improve how text is rendered in your write-ups and graphs.
- the {stringr} 📦 family for text manipulation
- grrrck s grrkmisc::pretty_num() for numbers
All these functions are handy shortcuts when automating write-ups in R.
I love doing this kind of stuff! Not only does it limit the scope for human error in copy-pasting info, it frees up precious time that you can then reinvest in the stuff that really needs your expertise. x.com/cararthompson/status/1577623068419141632
Full details here, where you can also make requests for other text-manipulating functions that would be useful!
github.com/cararthompson/verbaliseR
Also available on CRAN!
Logo by www.jennylegrandphotography.com/
Happy text manipulation with #rstats!
P.S. The tag line - Make your text mighty fine - is a pun, likely to be enjoyed by a select few Francophone #rstats users. I enjoyed it.
But cross-linguistic puns aside, if anyone wants to help internationalise num_to_text(), please give me a shout!

Reuse
Citation
For attribution, please cite this work as:
Thompson, Cara. 2022. “🚨 New #Rstats Package: verbaliseR.”
October 6, 2022. https://www.cararthompson.com/posts/2022-10-06-new-rstats-package-verbalise-r-a/.